DART Frequently Asked Questions
Categories and Questions
- Understanding DART
- Interpreting DART Data
- What will my DART results look like?
- What kinds of errors does DART make?
- Why doesn’t the decibel level look higher when many students are talking than it does when only the instructor is talking?
- My class session was nearly all Multiple Voice. Why does DART say that my class was all Single Voice?
- My small class or meeting had periods of Multiple Voice. Why did DART say that these periods were Single Voice?
- Using the DART Website
- How long will DART take to analyze a class session?
- What file types can DART analyze?
- What if I only have a video file?
- What should I do with my file before analyzing it with DART?
- What internet browser should I use to run DART?
- What type of recording device should I use to collect DART data?
- Where should I place the recording device within the classroom?
- What if I want to run a large number of audio files for a whole course or multiple instructors?
- HELP! DART isn’t working for me. What should I do?
Understanding DART
What is DART?
Decibel Analysis for Research in Teaching (DART) is a machine-learning-based algorithm that can analyze audio recorded class sessions with minimal costs and without need for human observers for measuring the use of teaching strategies beyond traditional lecture in undergraduate STEM courses. DART characterizes class session noise levels into three different modes: single voice, multiple voice, and no voice. Table 1 below shows common activities that are typically associated with each of these three modes. Based on our testing, DART makes an accurate prediction 87.5% of the time and tends to underestimate the amount of time spent in multiple and no voice. More on the types of errors DART makes in the section, What kinds of errors does DART make.
Table 1: Activities typically associated with different DART Modes
| Predicted DART Mode | Human Annotation Code |
|---|---|
| Single Voice | Lecture: Instructor or other individual speaking to class as a whole |
| Question/Answer: Individual student or instructor responding to class as a whole | |
| Video: Any audio/video clip played while students are sitting and watching/listening | |
| Multiple Voice | Discussion: Small groups of students talking with multiple voices talking in the classroom at once |
| Transition: Breaks, movement around classroom, time between activities when students might chat or make loud movements | |
| No Voice | Silent: Students working individually (no one talking) such as a minute paper, think portion of a think pair share, quiz |
Why did we build DART?
Active learning pedagogies of varying quality have been repeatedly demonstrated to produce superior learning gains with large effect sizes compared to lecture-based pedagogies. However, it is unclear what proportion of STEM instructors in the U.S. and internationally regularly use teaching strategies beyond lecture. DART meets this need for a measurement approach that could systematically inventory the presence of active learning not only in one course but also across dozens of departmental courses, multiple STEM departments, and thousands of colleges and universities.
Who built DART?
We are an interdisciplinary team drawn from more than two-dozen San Francisco Bay Area community colleges and universities led by the Science Education Partnership and Assessment Laboratory (SEPAL), the Center for Computing in Life Sciences (CCLS) at San Francisco State University, and research collaborators at Pacific Lutheran University. In total, the research team includes over 70 collaborators!
Who can use DART?
While we developed DART to analyze noise patterns in college science courses, we can think of many other applications for this tool. If you are an individual instructor, a K-12 teacher, a faculty developer, a program coordinator, or in another position in which you think DART might be useful to you, we would love to hear about it! Please use the button below to contact us and tell us how DART might be useful in your context.
Interpreting DART data
What will my DART results look like?
Your DART Report will include three main parts:
- A “clean” waveform showing classroom noise (decibels) over time (minutes)
- A DART prediction waveform that adds colored shading to the clean waveform to indicate the assigned DART mode: Single Voice (green), Multiple Voice (orange), and No Voice (blue)
- DART summary table that indicates the approximate amount of time DART identifies in each of the three modes.
What kinds of errors does DART make?
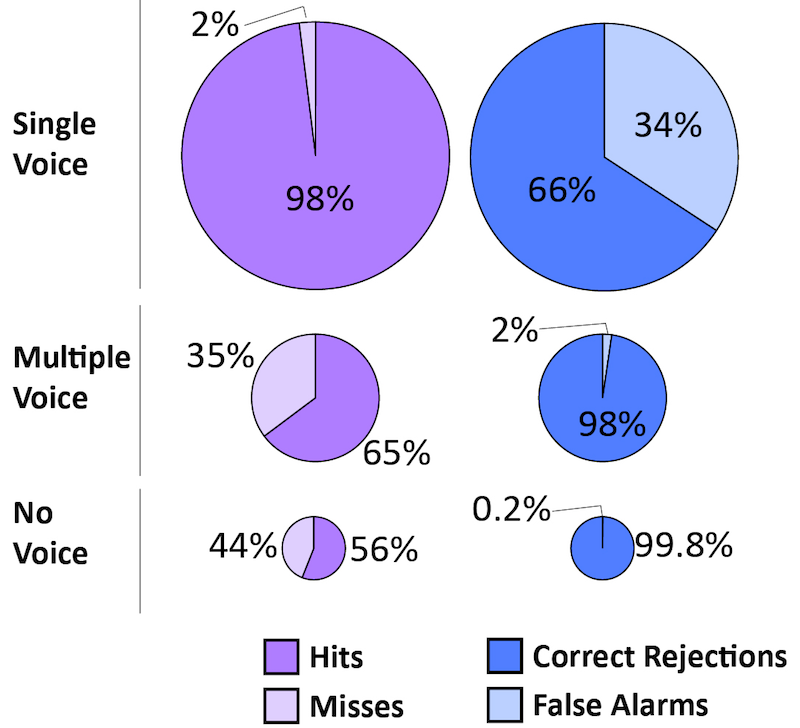
DART makes a conservative estimate of the amount of time spent in modes Multiple Voice and No Voice, the two DART modes that correlate most directly with student-centered or active learning activities. The pattern of errors DART makes for each mode showing correct inclusions (hits), incorrect exclusions (misses), correct exclusions (correct rejections), and incorrect inclusions (false alarms), can be seen in Figure 1 below.
Figure 1
More specifically, below we list some potential coding misclassifications that you may encounter:
| Examples of diverse classroom situations | Human annotation code | Expected DART mode based on annotation | Actual DART prediction | |
|---|---|---|---|---|
| (A) False Negative for Single Voice | Recorder is too far away from individual talking | Lecture with Q/A | Single Voice | No Voice |
| Long pauses where instructor is silent (e.g. while writing on the board or working with equipment) | Lecture with Q/A | Single Voice | No Voice | |
| Student closest to audio recorder talking inappropriately while instructor is talking | Lecture with Q/A | Single Voice | Multiple Voice | |
| Instructor talking during a video with audio or video with loud music | Video | Single Voice | Multiple Voice | |
| Significant ambient or outside noise (e.g. loud fan, outside hall conversations, etc.) during single voice activity | Lecture with Q/A | Single Voice | Multiple Voice | |
| (B) False Positive for Single Voice | Silent work in which an instructor or student speaks extraneously | Silent | No Voice | Single Voice |
| Significant ambient or outside noise (e.g. loud fan, outside hall conversations, etc.) during silent activity | Silent | No Voice | Single Voice | |
| Small group or pair discussions in a very small (e.g., under 4 student) class | Discussion | Multiple Voice | Single Voice | |
| Small or pair discussions in which there is delayed/minimal student discussions | Discussion | Multiple Voice | No/Single Voice | |
| (C) Errors Concerning Other Modes | Break during class – students remain in classroom | Transition | Multiple Voice | Multiple Voice |
| Students left classroom for small group activity | Silent | No Voice | No Voice | |
| Choral response to instructor questions (lasting more than 15s) | Lecture with Q/A | Single Voice | Single Voice |
(A) Classroom situations with a human annotation corresponding to Single Voice but DART prediction of Multiple or No Voice. (B) Classroom situations with a human annotation corresponding to Multiple or No Voice but DART prediction of Single Voice. (C) Classroom situations where predicted and actual modes match, but vary based on quality of activity.
Why doesn’t the decibel level look higher when many students are talking than it does when only the instructor is talking?
This may be an artifact of recorder placement (if the recorder is closer to the instructor than the students) or using pre-recorded audio to run the decibel analysis. Recording devices have a limited range, so samples at the high end and low end of that range will be given similar decibel values.
My class session was nearly all Multiple Voice. Why does DART say that my class was all Single Voice?
DART was designed to be a conservative estimate of the amount of time spent in the Multiple Voice and No Voice modes, so errors can occur when a recording is nearly all Multiple Voice (or nearly all No Voice, as during an exam). More specifically, because DART was designed to work with a variety of sound recording equipment and contexts, DART creates its predictions using sound loudness levels and sound variability levels normalized to the average loudness and variability level of the entire class session. If a class session includes a variety of modes, the relative sound patterns of these modes will contrast with each other and have different normalized loudness and variability levels. In contrast, if nearly all the class session is Multiple Voice, there is no contrast and no way for DART to tell the "true" mode. Given that DART was designed to be a conservative estimate of active learning, DART defaults to presuming that such "monomodal" recordings are all in Single Voice.
My small class or meeting had periods of Multiple Voice. Why did DART say that these periods were Single Voice?
In a recording of a small class or meeting, one with under 16 participants or so, a human listener can often still pick out the cadence of individual voices during pair or group discussions. As DART was designed to be a conservative estimate of the amount of time spent in the Multiple Voice and No Voice modes, DART tends to predict those times to be Single Voice.
Using the DART website
How long will DART take to analyze a class session?
The analysis time depends on the length of audio file as well as your computer’s processing speed and the strength of your internet connection. On a general use laptop computer, a 60 minute audio file will take approximately 5 minutes to complete analysis. We thank you for your patience.
What file types can DART analyze?
DART accepts files in MP3, MP4, M4A, M4P, OGG, and WAV format.
What if I only have a video file?
DART can analyze MP4 and M4P video types. If you have a video file in another format, you can extract the audio from it using any number of different programs online.
What should I do with my file before analyzing it with DART?
The percentages DART calculates are not valid if your recording includes noise from before class, after class, or breaks. Therefore if you'd like percentage data, please clip your file to exclude time before or after class or during breaks. Many free downloadable programs are available that you can use to clip your files, including Audacity and iTunes.
What internet browser should I use to run DART?
Our early testing indicates that DART will run in Chrome, and Firefox but not Safari. While either works, Chrome is best supported. Browsers on phones and tablets are not supported.
What type of recording device should I use to collect DART data?
For our initial study of DART, the Sony Digital Voice Recorder ICDPX333 was used. However, other recording devices such as basic video cameras and iPhone Voice Memo have been used to record audio samples with similar results. However, microphones that selectively record sound in a particular direction (such as "cardioid" microphones) may not work as well, because they exclude the background noise. Therefore, while we anticipate that most audio recording devices should give usable DART results, we cannot guarantee it, so we recommend that you try yours out and run DART analysis on it to see if it is effective before doing any long-term recording projects.
Where should I place the recording device within the classroom?
In our experience, it was most effective to place the recording device at the front of the classroom (perhaps on a podium or table) with the recording device facing the audience. It is important to note that the recording device must be able to hear both the instructor’s voice and the students’ collective voice.
What if I want to run a large number of audio files for a whole course or multiple instructors?
If you have many files or instructors to analyze, please contact us with the button below to discuss a potential collaboration.
HELP! DART isn’t working for me. What should I do?
We are doing our best to make DART accessible to everyone who would like to use it. If you are having trouble, make sure you are using the supported browsers, either Firefox or Chrome. You can also first try closing other programs and see if DART works. If you are still having trouble, please share your issue with us by contacting us using the button below. It will be most useful if, to the extent you can, you can share information about what computer and browser you are using and what else you are running. Thank you for your patience as we get this tool up and running!